Web Scraping Gaming Data from Steam Platform Using Python



In this blog, we will write Python code to extract all the required game data from the leading game-selling website Steam. Our code will extract all the data, including the title, price, link, and release date of games, in the desired format. Further, the code will crawl all the gaming Information according to the search queries we will search on the platform. In the last step, we will convert the scraped gaming data into CSV, JSON, and Excel. For scraping, we need some Python libraries like Beautifulsoup4 and Requests. We will also use pandas and JSON libraries to convert the data into CSV, JSON, or Excel format. Lastly, we need an os package to make a file to store the final output.
To scrape Steam gaming data, we import the above Python libraries. If you still need to install them, you should install them. After installing the necessary packages, we will generate a link variable with the URL https://store.steampowered.com/search/results. Our code aims to extract data for all games that we have searched for, so there may be a chance of error. If there is any error during the data scraping, you can install openpyxl.
After that, we make a game variable to locate the keyword input we need to search. Hence, executing our code will ask for the game input we want to collect. Once we submit the input, our code will extract all the required data from Steam as per entered keywords.
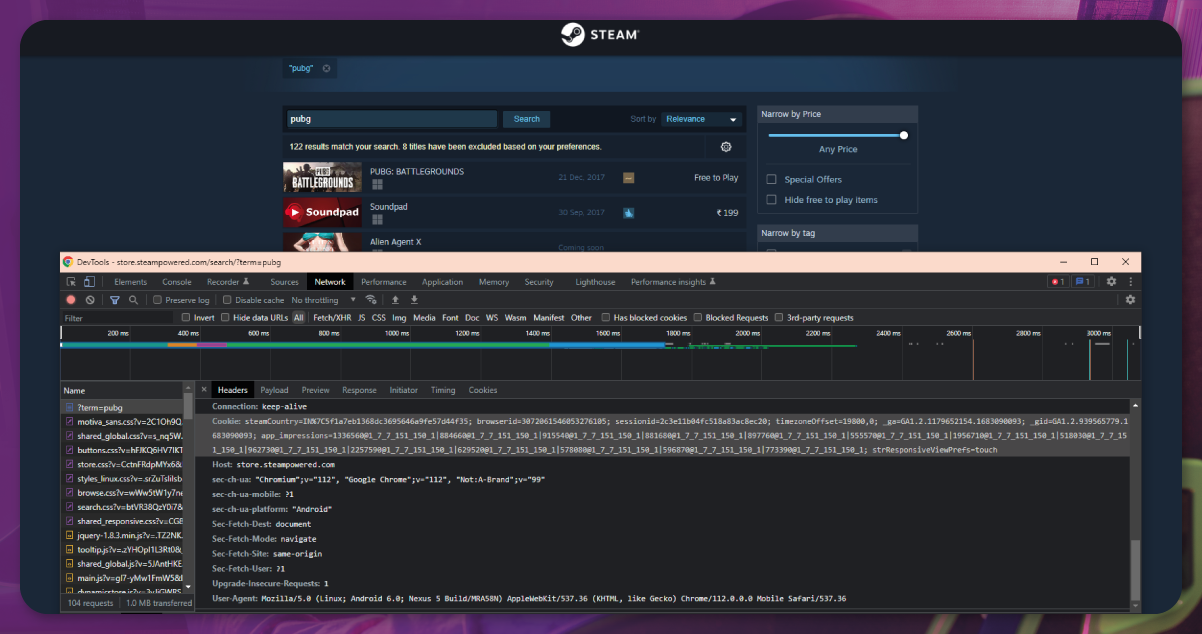
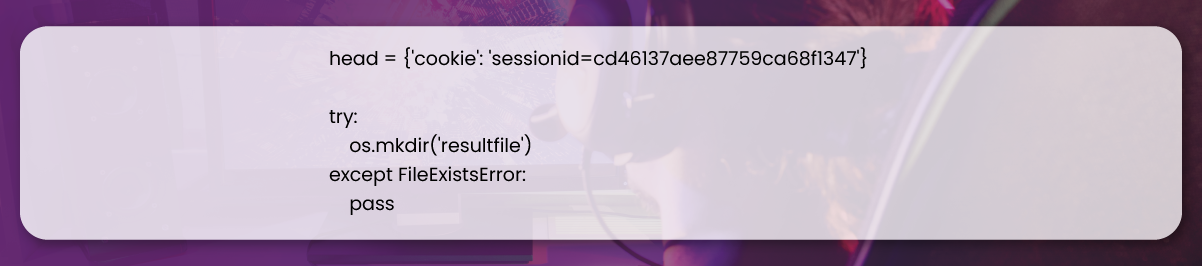
In the third step, we used a dictionary containing the session ID to create the head variable. We have considered this variable as an additional parameter to protect the execution from detection by the source. Follow the below process to discover the session ID.
Choose the network menu
Choose the top file
Open the cookies section
Find the session ID
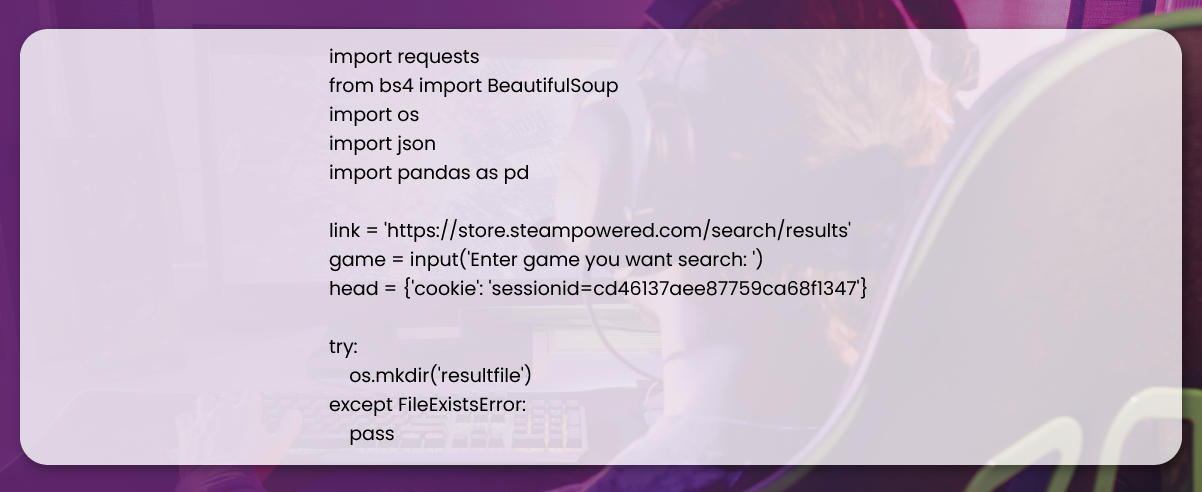
After the above process, we make a new folder to store the scraped data files when we run our code. If the folder doesn't exist, we create a new folder. But if it is available, we don't need to create a new folder; we use error handling to fulfill this. You can easily create a new function using the mkdir function from the os package and name the function according to your requirements.
Check the early-stage code below.
After the above steps, we will make a function to search the last page of Steam game data we are hunting, namely get_pagnition(). Firstly we create a param variable in this function. The param variable is similar to the head variable in terms of functionality. When we call the Requests library, call the function as an additional parameter. There are two values in the param function. The first term uses game keywords as value, and the second is a page with one as the value. We kept the one as the value because we wanted to retrieve only one page. Depending on requirements, the page will change the available page count in the following function.
Then, we will create a req variable that contains the Requests library and get function. There are extra headers and params parameters. Later, we create a soup variable to input the req.text variable, locate the BeautifulSoup library, and use the HTML parser. Then, we search for the page tag location.
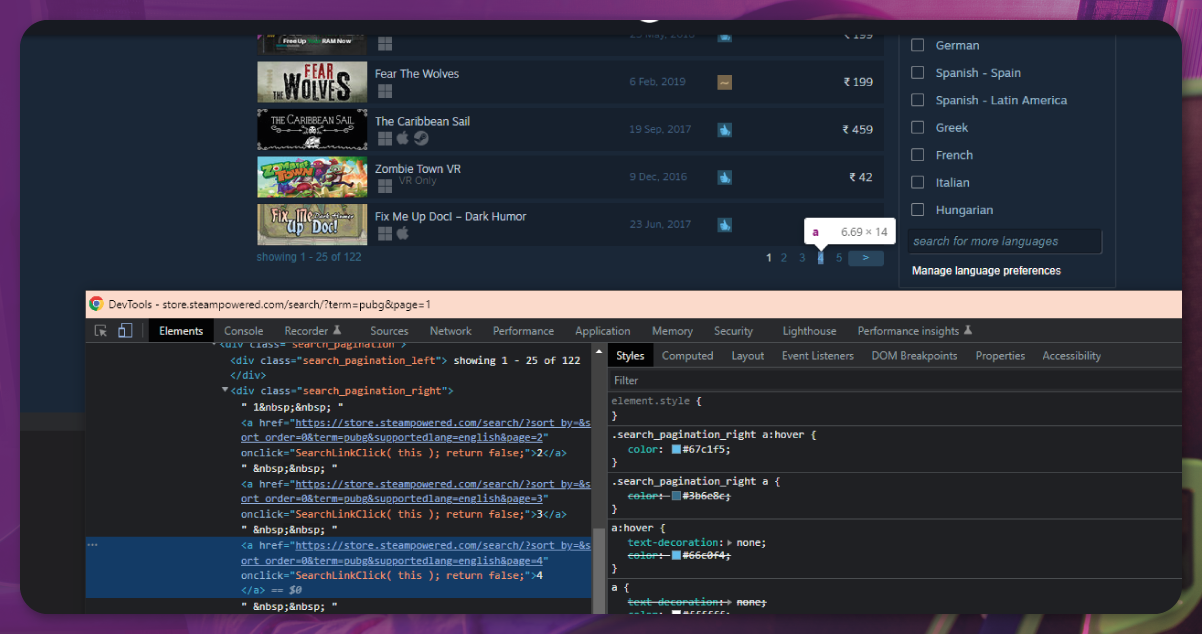
If we check the above HTML structure, we should find the search_pagination_right class first, then find_all tag to get each number in the search_pagination_right class. After that, we save this function in another variable, page_item, to call it. Since the variable page_item is near the finishing find_all, this variable's data type is the list. We use the error handling to get the last page_item list number when the number in the fifth list is the largest. We keep doing the same process until we get the last number. We will take the one as the order value if there is only one page. Consider that we can return one extra page than total_page. Then we must ass our goals to the first number because computer calculations begin from zero. We should add 1 to get the number according to our expectations.
Check the code below for the get_pagination function we wrote.

In the next step, we make a web scraping function of each data, namely scrap(). It has the role of creating a serial number for every data available to us. Additionally, we create a data variable using a list type of data to serve as a data container. We use a loop to access each page with two ranges to the function get_pagnition we initially created. Firstly we make a counter variable with 0 to make the scrap function. Then we make a param variable with a value similar to the param variable available inside the get_pagination() function. Then, we make soup and req variables similar to those in the get_pagination(). Since we are using a loop, the page item has a rising value.
Now, it is time to collect all the required data. Firstly we should see the target tag that we will use.
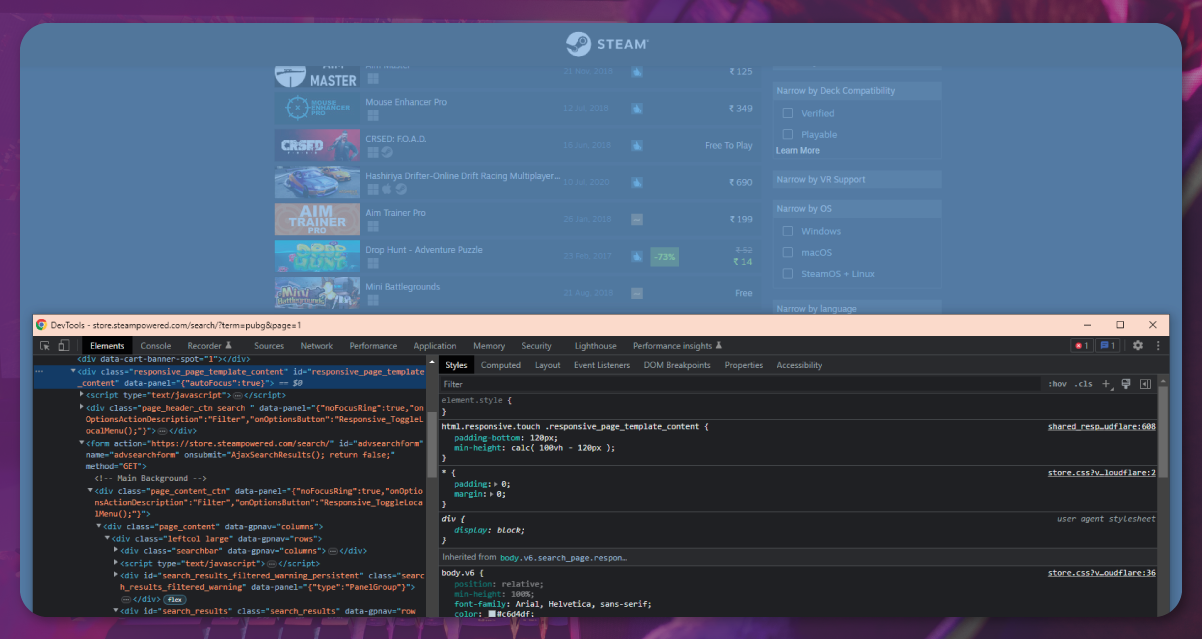
Considering the above HTML structure, every fame data is available in the div tag with the search_resultsRows id. Every game exists in the tag, so we discover the div tag with search_resultsRows id. Then, we find every tag to get all the game data and locate it in the content variable. After getting all the game data, we parse it according to our needs as we use the loop since data is available as a list inside the content variable. We will collect titles, links, release dates, and price data. After getting the data, we feed it to the dictionary variable and put the dictionary in the data variable that we initially created. The function will simplify extracting the gaming data in Excel, CSV, and JSON files. Make sure to use the syntax i+=1 as a continuously growing counter. Finally, we will print all the scraped data per the following code.

While extracting title data, we have used the strip and replace syntax, which deletes the space available in front of the text and removes newlines in all data. Besides, while collecting pricing data, we have used the try-except function using the condition that we can take the data from the discount tag if there is a discount on the game. We follow the same process while scraping date-release data. We only take a value if price information is available while scraping price data.
We've completed the process to scrape Steam game data and can now extract it. To extract it, you need to write and execute the code without using a loop to avoid repetition of extraction. Initially, we will extract the data in a JSON file. Then we retrieve it in the CSV and Excel files. For this, we use the pandas library. You can expect a change in the file name because of the game variable. Give a false value to the index. Remember to install the openpyxl package to retrieve data using pandas.
Conclusion
This way, we have created a Python code to scrape Steam game data. If you want a customized solution for web scraping gaming data from Steam, contact Actowiz Solutions.
sources : https://www.actowizsolutions.com/web-scraping-gaming-data-from-steam-platform-using-python.php